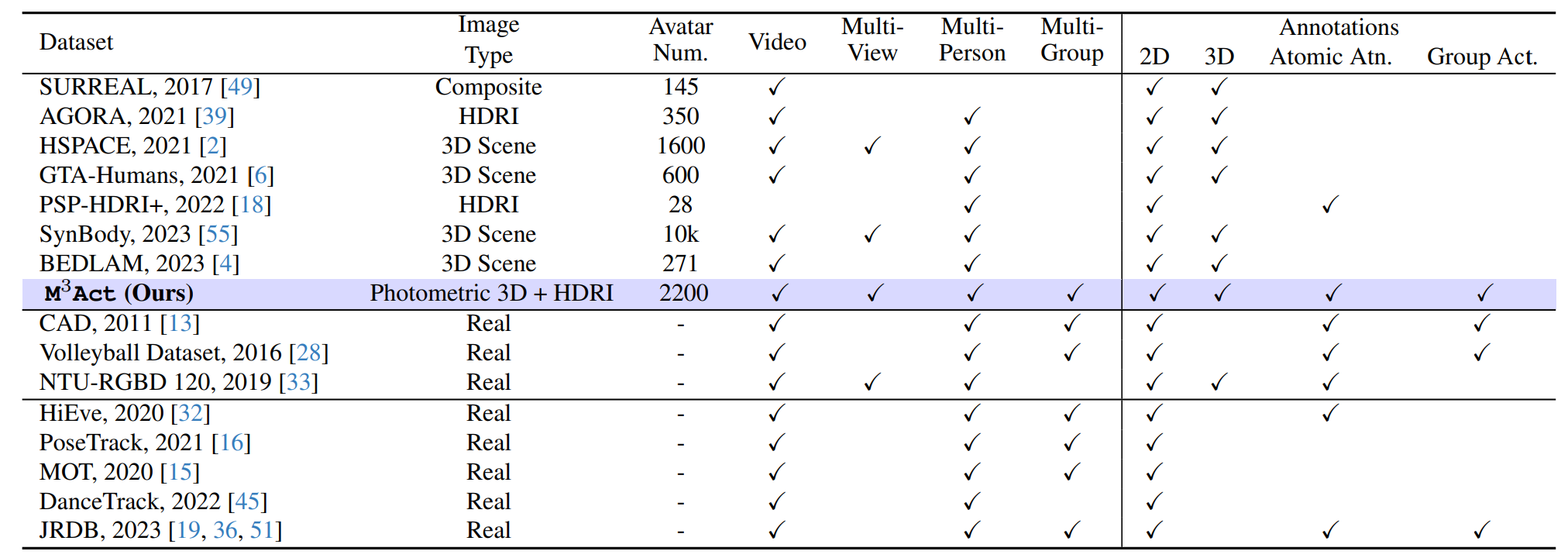
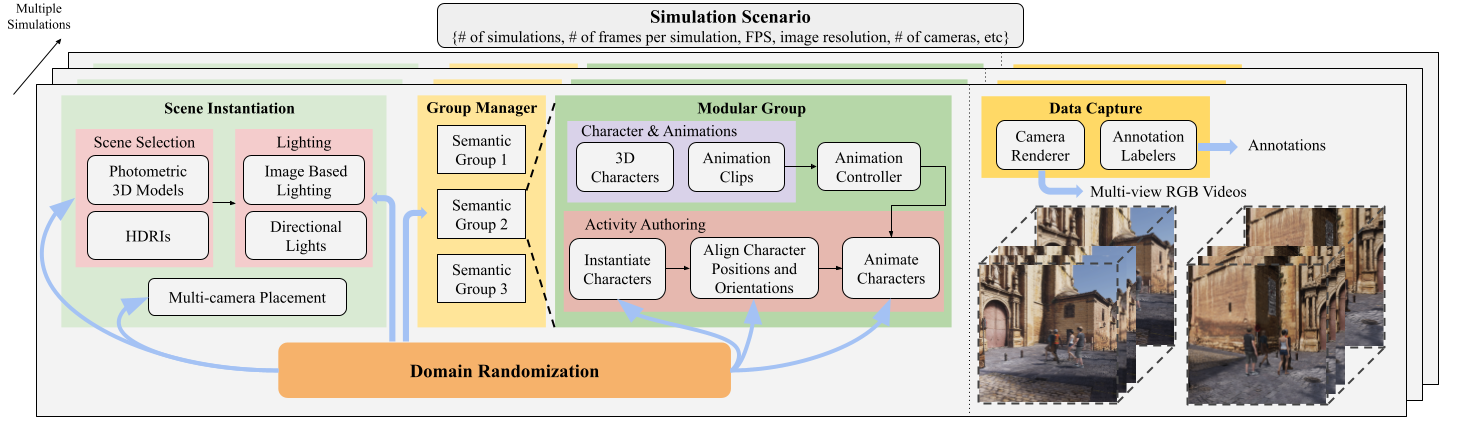
TLDR. We introduce M3Act, a synthetic data generator for multi-view multi-group multi-person atomic human actions and group activities. M3Act is designed to support multi-person and multi-group research. It features multiple semantic groups and produces highly diverse and photorealistic videos with a rich set of annotations suitable for human-centered tasks including multi-person tracking, group activity recognition, and controllable human group activity generation.